
Attention Is All You Need notes
Link to the original research paper : click here
Introduction.
Recurrent neural networks ( RNN ), long short-term memory ( LSTM ) and gated recurrent neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation. However the inherently sequential nature of those models precludes parallelization within training exemples, which becomes critical at longer sequence lengths, as memory constraints limit batching accross examples.
⇒ That's why attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences.
In this paper, the authors propose the Transformer, a new model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.
Background
Quick reminder of some basic notions :
Self attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence and has been used successfully in a variety of tasks including :
- reading comprehension
- abstractive summarization
- textual entailment
- learning task-independent sentence representations
End to end memory network are based on on a recurrent attention mechanism instead of sequence-aligned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks.
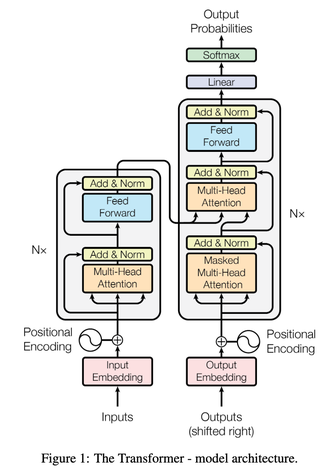
Model Architecture
Most competitive neural sequence transduction models have an encoder-decoder structure so that will also be the basic structure in the Transformer model.
Here the encoder maps an input sequence of symbol representations (x1, . . . , xn) to a sequence of continuous representation z = ( z1, . . ., zn ). Then, given z, the decoder generates an output sequence ( y1, . . ., yn) of symbols, one element at a time.
At each steps the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
Attention
An attention function can be described as mapping a query and a set of key value pairs to an output where the query, keys, values and output are all vectors.
The output is computed as a weighted sum of the values where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
Scaled Dot-Product attention
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix Q. The keys and values are also packed together into matrices K and V.
We compute the matrix of outputs as
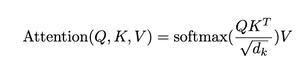
n.b. The two most commonly used attention functions are :
- additive attention
- dot product (multiplicative)
⇰ Dot product attention is identical to our algorithm, except for the scaling factor.
⇰ Additive attention computes the compatibility function using a feed-forward network with a single hidden layer.
Multi-Head Attention
Multi-Head Attention allows the model to jointly attend to information from different representation subspaces at different positions.
The model here uses multi-head attention in three different ways :
- In encoder-decoder attention layers, the queries comes from the previous decoder layer, and the memory keys and values comes from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence mimicking as such the typical encoder-decoder attention mechanisms in sequence to sequence models
- The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
- Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position.
⇒ In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network which is applied to each position separately and identically.
Moreover, since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence by adding positional encodings to the input embeddings at the bottom of the encoder and decoder stacks.
Results
For translation tasks the Transformer model can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English to German and WMT 2014 English to French translation tasks we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles.
By the way, as side benefit, self-attention could yield more interpretable models. Indeed, not only do individual attention heads clearly learn to perform different tasks, many appear to exhibit behavior related. to the syntactic and semantic structure of the sentences.

All information/documents contained in this website rely solely on my personal beliefs, and do not constitute professional investment advice.
Be careful in your investment and do not invest more than you can afford to loose.
Contact :
e-mail: christophe.richon.pro@gmail.com