Definition of the vanishing gradient problem :
During the training of a neural network (NN), as the error is back propagated from the ouptut layer back towards the input layers through the network, it turns out that the gradient of the error term with respect to the weights value diminish which is a problem knowing that the gradient descent based algorithm involved in NN update the weight values based on the magnitude of these gradients. In this sense if the gradients grow too small, the network will train very inneficiently, this is what we call the vanishing gradient problem.
The source of the vanishing gradient problem
The weight and bias values in the various layers within a NN are updating during each optimization iteration by stepping in the direction of the gradient of the weight/bias values with respect to the loss function. In other words the weight values change in proportion to the following gradient :

with :
- C : the cost or loss function at the output layer
- Wl : the weight of the layer l
At the final layer, the error term δ looks like :

with :
hi( nl ) : the output of the network
yi : the training the label
f' ( zi(nl) ) : the derivative of the activation function
For earlier layers the error from the latter layers is back-propagated via the following rule :
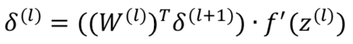
So basically, the gradients of the weights of a given layer with respect to the loss function, which controls how these weights values are updated, is proportional to chained multiplications of the derivative of the activation function, i.e. :
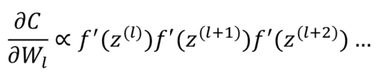
From here we can see that the vanishing gradient problem comes in deep neural net when the derivative terms are all outputting values <<1 which leads to a very small gradient and hence practically no learning of the weight values causing as such the predictive power of the neural net to plateau.

All information/documents contained in this website rely solely on my personal beliefs, and do not constitute professional investment advice.
Be careful in your investment and do not invest more than you can afford to loose.
Contact :
e-mail: christophe.richon.pro@gmail.com