Machine learning part 1 : support vector machine
Hi there ! Hope you're doing great ! 😃
In order to start this new series of tutos about machine learning I thought that it would be cool to start slowly with what we called the Support Vector Machine or SVM which thanks to the very useful scikit-learn library is very easy to compute and play with, before going deeper and approach other models such as neural networks and so on.
Ready ? Let's go then 😀
First, let's make a quick recap of the notion of SVM ?
Created by Vladimir Vapnik in the 60's and brought back from the dead in the 90's, the support vector machine most commonly known as SVM is one of the most, if not the most popular, classifier currently used in the machine learning field. Moreover, it's objective is rather simple and straightforward : find the best splitting boundary among our data.
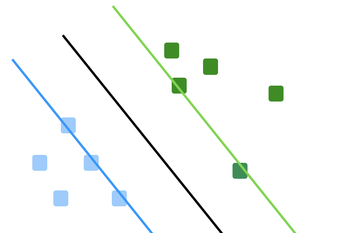
In the context of this tuto we will not go into further details about the definition of SVM as I already wrote an article about it in the theory section 📝 and I assume that if you're here to get a tuto about SVMs you probably know what they are 😉. However, if you don't or need a deeper recall don't hesitate to go read this article and come back once you're more at ease with the theoretical concept at play.
Now, let's code our first SVM !
As I mention earlier in order to compute our SVM we will need the scikit-learn library so if you don't already have it on your system download it using pip :

About the data ?
Here we will use the UCI banknote authentication dataset which analysis the authenticity of a set of banknotes given the following characteristics :
- variance of Wavelet Transformed image
- Skewness of Wavelet Transformed image
- Curtosis of Wavelet Transformed image
- Entropy of image
- Class ( authentic/False banknote )
Note : As you can spot if you go check the data right here, we don't have any name for our columns, so we have to give them one ourselves.

Moreover, due to the supervised nature of our machine learning model we will need to dispose of a training & test data set in order to be able to train our SVM. To do so, what we are proposing here is to divide our dataset by a 80/20 ratio with the help of the train_test_split method :

Now, the only remaining thing left to do is to call our model and check its accuracy which, thanks to the scikit-learn library, is pretty straightforward as shows the code below :
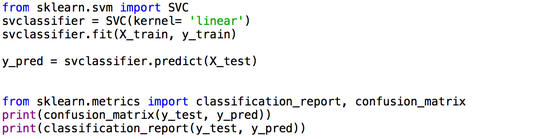
And that's it, we've made our first SVM model ! 😃 As always you will find the full code for this tuto here and don't hesitate to play a little bit with this SVM by changing the data and all before continuing into the next tutos where we will build an SVM from scratch and go a little bit further with more complex models.
See y'all !

All information/documents contained in this website rely solely on my personal beliefs, and do not constitute professional investment advice.
Be careful in your investment and do not invest more than you can afford to loose.
Contact :
e-mail: christophe.richon.pro@gmail.com