
Summarizer Part. 2
Hi everybody, hope everything is doing fine on your side
In this tutorial we will continue our work on summarization techniques and in line with the previous tutorial on this subject approach the second main methodology for summarizing batch of text called the abstractive method. However, as always when we are talking about NLP, there is not only one algorithm available as shows the quite furnish academical litterature on this subject. In this sense and in order to keep things simple and understandable without too much prior knowledge on the matter, we will use here a seq2seq algorithm with a two-layered bidirectional RNN with LSTMs on the input data in order to create a model capable of creating relevant summaries for reviews written about food goods sold on Amazon.
Important Note :
In this tutorial I made the choice of using Google Colab GPU as in the first tutorial given the volume of data that we'll have to handle during the training of our model, so if you decide to use another set up to follow along this tutorial be aware that you'll have to make some little adjustments to upload the data.
As always full code is available here
But enough talking let's dive into the code !
PART 1 : DATA PREPROCESSING
First we're going to have to mount our google drive into our new colab notebook and install the kaggle library which is not installed by default.
Then as usual we import the libraries that we'll use in our code and also initialize our variables for the kaggle API given that the datset that we'll use is stored on kaggle.
The environment being set up, we can then download our data from kaggle directly into our drive and create a dictionnary of common contraction that will allow us to correctly format our data for the model.
Now, once our data is uploaded in our drive and at our disposal, we will have to format it before being able to use it in our model.
To do so we will apply the following methodology :
- Extract the data and only keep the useful inputs
- Clean our string inputs by removing stopwords, unwanted characters etc
- Create a word dictionnary based on our cleaned Amazon dataset
- Create an embedding index and fill up the gaps for words outside of this index
- Discriminate our inputs to only keep the most used words and not confuse the model by adding non relevant words
- Create an embedding matrix based on this discriminate set of inputs
- Convert our words into integers, calculate the total of words & [ UNK ]* tokens and add an [ EOS ] token at the end of each Amazon summary / review.
- Create a dataframe of the sentence lengths for all the Amazon reviews in order to sort out our summaries
So let's start with extracting our data. To do so we will have to remove the useless inputs implented in our initial dataset such as Product Id or Profile Name and clean it a bit by removing all the cases where we have a NaN value.
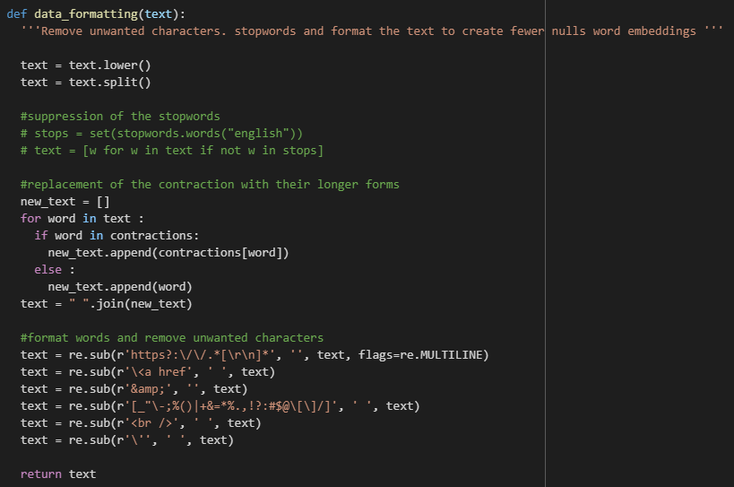
Following the same idea, we now operate a deeper cleaning of our data and remove all the stopwords and unwanted characters that our inputs dataset inevitably contains :
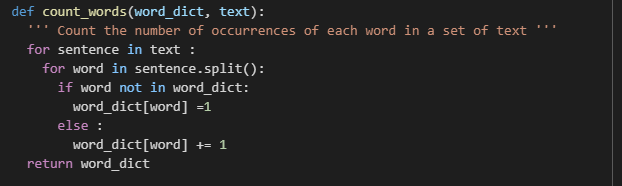
Once, we're done cleaning our data inputs, we can create our word dictionnary regrouping all the different words contained respectively in our cleaned Amazon summaries and reviews.
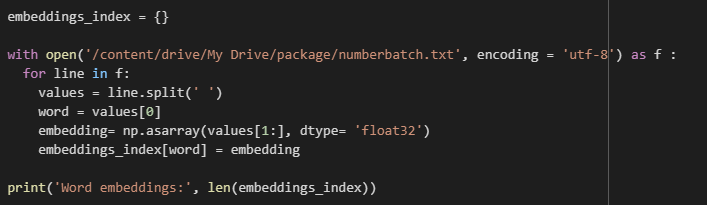
To create our embedding index, we directly build it on top of the ConceptNet Numberbatch that allows us to dispose of a set of semantic vectors and can be used directly as a representation of word meanings.
Link to ConceptNet file : numberbatch-19.08.txt.gz
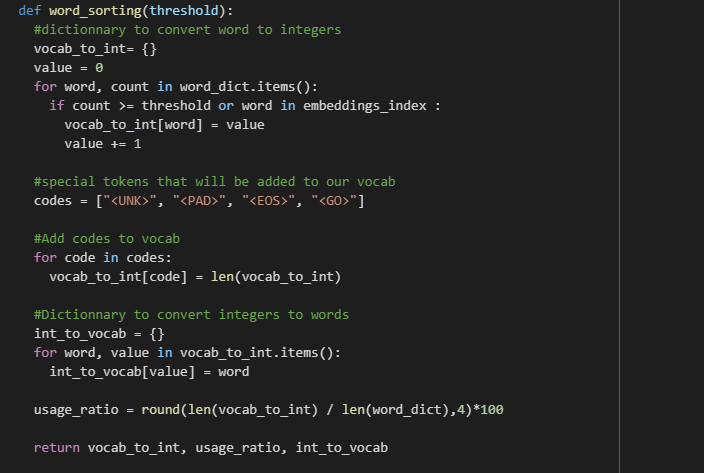
In order to not add too much noise in our model during the training and get the most accurate results possible, it is a good idea to discriminate our inputs and only keep the most frequent words.
N.B. We are here considering a threshold of 20 words but feel free to experiment other values on your own to see for yourself if it allows you to reach better results.
Based on this discriminating set of inputs, it is now time to create our embedding matrix :
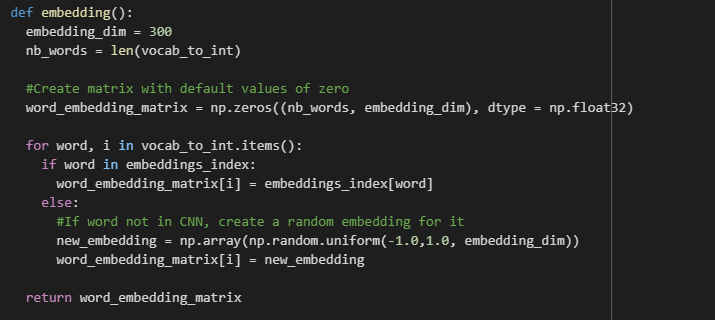
And finally in order to finish this preprocessing of our data we convert our words, as integers thanks to our word dictionnary and then calculate the total words and unknown tokens in our formatted inputs to be able to create a sorted dataframe of our sentence lengths for all the Amazon reviews.



And that's finally it for our data preprocessing !
It was indeed a preety big chunk to swallow so if you need to make a little break to freshen your mind don't hesitate to make one, go grab a coffee or something and come back after it for the second round where we're going to see how to build our model architecture.
PART 2 : MODEL BUILDING
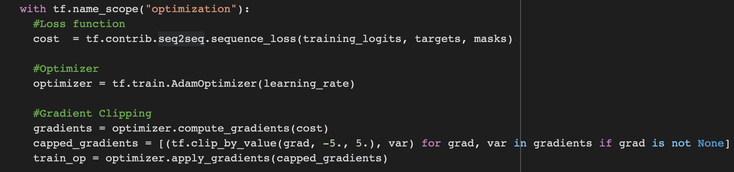
Now that we dispose of a formatted input dataset, it is time to create our model and build its core infrastructure by creating and setting our graph to default before fine tuning it and introducing our loss function / optimizer / gradient clipping
n.b. If you need a quick reminder on the notion of graph go check out this article


PART. 3 MODEL TRAINING
Here the code is pretty straightfoward. Indeed in a first step we initialize all our required variables as follows :

Then using the tensorflow Session instance and our graph we start training the model for the required number of periods and gradually lower the learning rate of our model until it hit the set minimum value.


PART. 4 MODEL TESTING
Now that we have a trained model it is time to play around a bit with it using our initial dataset to see if the results that we get are satisfying enough.
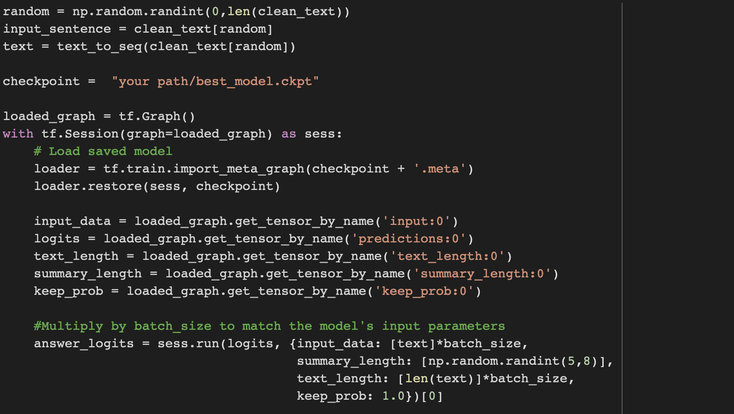
To do that, we'll first need to format the test data as follows :

Then, once we're good to go with our data we call the best version of our model that we obtained during our training and run it on our input before printing the results.
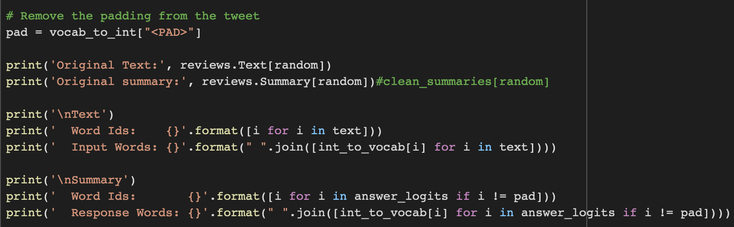
Original Text: This shampoo cleans well and leaves your hair soft, but I can't discern any difference between this and most other shampoos on the
market. It has a light, pleasant scent -- not too perfumey -- and it lathers well. I would use it again, but it's nothing to get super-excited about. Regarding the claim about
getting your hair stronger in seven days, I honestly can't say I noticed that.
Original summary: Good, But Nothing Special
Text
Word Ids: [105, 470, 763, 818, 3877, 9960, 3866, 9020, 740, 9987, 4440, 7700, 1055, 934, 822, 1514, 44, 3877, 9960, 3866, 9020, 740, 9987,
4440, 9878, 1055, 1223, 822, 1514, 70, 849, 3560, 2530, 8109, 79, 228, 16, 85, 381, 625, 79, 0, 1484, 102, 461, 295, 79, 2603, 2723, 28, 30, 3866, 332, 17, 705, 7700, 70, 2612, 3785, 105, 671,
763, 477, 10263, 7802, 28, 30, 9768, 833, 20457, 411, 30, 3950, 3866, 332, 818, 64, 2060, 70, 17, 705, 104, 461, 295, 175, 486, 3866, 5381, 6439, 28, 17, 9768, 332, 15137, 44, 9023, 79, 1766, 41,
3324, 461, 748, 67, 1416, 940, 10263, 28, 17, 9768, 139, 10, 105, 470, 7860, 849, 3560, 85, 2646, 424, 64, 2060, 93, 10981, 216, 17, 3866, 12562, 787, 30, 1008, 3866, 16, 12475, 949, 17, 986, 41,
61, 9043, 124, 102, 461, 465, 4, 3864, 85, 366, 940, 9043, 124, 139, 10, 238, 2475, 30, 3866, 12962, 293, 102, 4, 11574, 44, 101, 5054, 105, 295, 1823, 308, 1457, 61, 73, 3877, 916, 39, 6010, 28,
1154, 366, 6236, 9, 3384, 101, 334, 61, 85, 502, 124, 79, 1346, 9989, 155, 86, 411, 394, 44, 1752, 85, 9, 685, 51, 106, 366, 15276, 70, 79, 1660, 105, 380, 32, 916, 64,
2060]
Input Words: i have been using clear scalp hair beauty strong lengths nourishing shampoo 12 9 fluid ounce and clear scalp hair beauty strong lengths
nourishing conditioner 12 7 fluid ounce for three weeks before writing a review just to give them a good test but there was a noticeable improvement in my hair after the first shampoo for several
months i had been getting hairs caught in my comb when combing out my wet hair after using these products for the first time there was only one hair left behind in the comb after shampooing and
conditioning a couple of times there were no longer any hairs in the comb at all i have waited three weeks to see if these products would accumulate on the hair strands because my fine hair just
collapses under the weight of product build up but there does not seem to be any build up at all they leave my hair manageable soft but not limp and very shiny i was surprised that neither
product is clear both are pearly in color be advised it takes very little product to work up a rich lather so start out small and add to it or you will be rinsing for a while i really love both
these products
Summary
Word Ids: [101, 0]
Response Words: very good
So, as you can see the results are not as good as we could expect in certain cases as the one shown above but the thing is that we only trained on a small subset of our initial dataset so evidently our best model is very far from the best version that you could get if we trained it properly.
Nonetheless in many instance the results are quite satisfying so I'll leave you to it and as always don't hesitate to play around with it and see if you find ways of improvement in the code or in the structure of the model by using a different loss function or optimizer.
See y'all !

All information/documents contained in this website rely solely on my personal beliefs, and do not constitute professional investment advice.
Be careful in your investment and do not invest more than you can afford to loose.
Contact :
e-mail: christophe.richon.pro@gmail.com