
Summarizer Part 1
Hi there ! 😊
Today we're going to approach Natural Language Processing and more specifically the concept of text summarization which as you know is divided into two main subsets :
- Text extraction
- text abstraction
However in this first part we will focus exclusively on the extraction methodology through the implementation of the three following summarizer :
- NLTK
- Gensim
- Summa
( -> if you need a quick reminder about text summarization and the theory behind it don't hesitate to go check out this article and come back after 😉 )
But enough talking already , let's code !
Quick disclaimer : In order to implement this litte algorithm that you'll find below I decided to use Colab so if you want to follow step by step this tuto and have the same view and stuff here is a quick tuto on how to get started with Colab.
First let's install the libraries that we'll need later on :
Now that we are set up, let's get down to the algorithm.
The idea here will be to summarize a Wikipedia article of our liking through different summerizer using the extraction technique in order to see their performance and be able to compare it.
So as you can guess, we will first need to build a scraping function in order to retrieve the text of the Wiki article that we desire :

Then once we have scraped the text of the wiki page it's pretty straight forward for the Summa and Gensim summarizer. As you can see we just have to use the summarize and keywords function coming from the gensim.summarization package in order to obtain from the gensim summarizer our summary and our keywords :

and then do pretty much the same for the summa summarizer :

Let's approach now the case of the NLTK summarizer which is a bit more tricky. The idea behind the NLTK summarizer is to go through the text corpus and calculate the frequency of each word in order to then attribute a score to each sentence based on the frequency of the words composing it. This score allowing us to then compute a summary with the sentences composed of the most frequent words of the article.
To do this we're going to implement a two step strategy. First we compute each word frequency in our text corpus by tokenizing each sentences of our Wiki article and use a dictionnary with each words as the dictionnary keys and the number of occurences of the words as values in order to then be able to divide each value of this dictionnary by the length of the very same dictionnary to obtain a frequency dictionnary regrouping each word with its frequency of occurence.
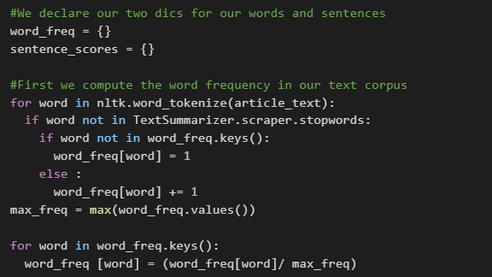
Then in a second step, we compute the score of each sentences based on the frequencies of their words and create a summary according to the ranking of each sentence score.

One more important thing to note though, is that due to to the nature of the packages implementation in Python you'll have to import the summa packages just before running the code to be able to obtain the summa summary and then rerun the code importing the gensim packages if you want to run again the code for the gensim summarizer or else you will obtain the following error
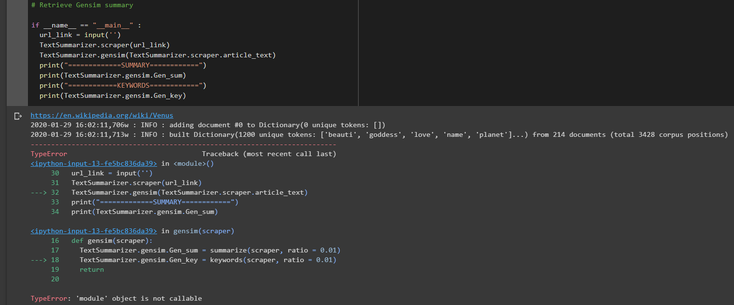
n.b In the code above I decided to create a class called TextSummarizer for ergonomic purposes however if you want to have the version without the class implementation I put another version on Github that you can go check out.
And that's it you can now enjoy a pretty simple but pretty satisfying summarizer given the little effort that we put into it.
As always you cand find the complete code on the Github page and don't hesitate to try playing around and adapt it to your needs.
See ya'll ! 😃

All information/documents contained in this website rely solely on my personal beliefs, and do not constitute professional investment advice.
Be careful in your investment and do not invest more than you can afford to loose.
Contact :
e-mail: christophe.richon.pro@gmail.com