Apriori Algorithm
Hi there, hope you're doing great ! ^^
Today we're going to explore a different type of algorithm called Apriori mainly used in data mining in order find relationships between differents elements of a
same database. One of the famous application of this algorithm being the Wal-Mart's beer diaper story where after the application of this algorithm on a database regrouping the yearly customer
sales the data scientist spot a relationship between the sales of diapers and beers enabling then the marketing team to create new group offers of beer and diaper and increase of the two products
sales in the following quarters.
However, as always in this serie, before seeing how we can implement this algorithm with python and start taking advantage of it, let's make a quick recap of the
theory behing it to understand a bit better its inner working and how and when to implement it.
Theory
As explained before the Apriori algorithm is a classical algorithm in data commonly used for mining frequent itemsets and relevant association rules. But before
going any further and see the general process of the algorithm let's do a quick recap of the following fundamentals notions
- the association rule
- the support
- the confidence
- the lift
- the conviction
Association rule
Let I = {i1, i2, i3, ... , in} be a set of n attributes called items and D = {t1, t2, t3, ...,
tn} be the set of transactions. A rule can be defined as an implication, X -> Y where X and Y are subsets of I, (X,Y) ⊂ I and they have no element in common, i.e, X ∩ Y. X and
Y are the antecedent and the consequent of the rule, respectively.
Example
Let's consider the set of itemsets, I = [Onion, BUrger, Potato, Milk, Beer] and a database consisting of sic transactions where each transaction is a tuple of 0's
and 1's where 0 represents the absence of an item and 1 the presence.
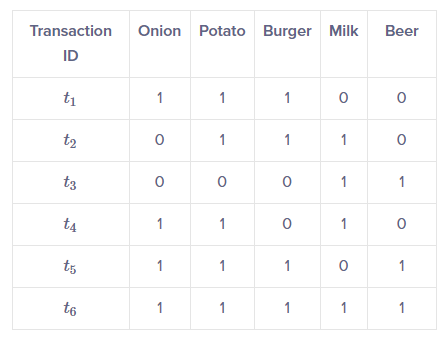
An example for a rule in this scenario would be [Onion, Potato] => [Burger] which means that if onion and potato are bought, customers also buy a
burger.
Support
the support of an itemset X, supp(x) is the proportion of transaction in the database in which the item X appears. It signifies the popularity of an
itemset.
supp(X) = Number of transaction in which X appears / Total number of transactions
=> If the sales of a particular product above a certain proportion have a meaningful effect on profits, that proportion can be considered as the support
threshold. Furthermore, we can identify itemsets that have support values beyond this threshold as significant itemsets.
Confidence
Confidence of a rule is defined as follows :
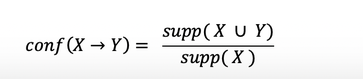
It signifies the likelihood of item Y being purchased when item X is purchased.It can also be interpreted as the conditional probability P(Y|X), i.e. the
probability of finding the itemset Y in transactions given the transaction already contains X.
=> It can give some important insights, but it also has a major drawback. Indeed, it only takes into account the popularity of the itemset X and not the
popularity of Y. If Y is equally popular as X then there will be a higher probability that a transaction containing X will also contain Y thus increasing the confidence. To overcome this
drawback, there is another measure called lift.
Lift
The lift of a rule is defined as:

This signifies the likelihood of the itemset Y being purchased when item X is purchased while taking into account the popularity of Y.
=> If the value of lift is greater than 1, it means that the itemset Y is likely to be bought with itemset X, while a value less than 1 implies that itemset Y is
unlikely to be bought if the itemset X is bought.
Conviction
The conviction of a rule can be defined as :

If we take back our previous database, the conviction value of 1.32 that we obtain for the rule [onion, potato] -> [burger] would mean that the rule is incorrect
32% more often if the association between X and Y is an accidental chance.
Alright, so now that we redefine these fundamentals notions, let's see how the Apriori algorithm works ^^
The entire algorithm can be divided into two steps:
Step 1 Frequent itemset generation : Find
all itemsets for which the support is greater than the threshold support following the below two step process :
1 : Apply minimum support to find all the frequent sets with k items in a database
2 : Use the self-join rule to find the frequent sets with k+1 items with the help of frequent k-itemsets. Repeat this
process from k=1 to the point when we are unable to apply the self-join rule.
=> This approach of extending a frequent itemset one at a time is called the "bottom up" approach.
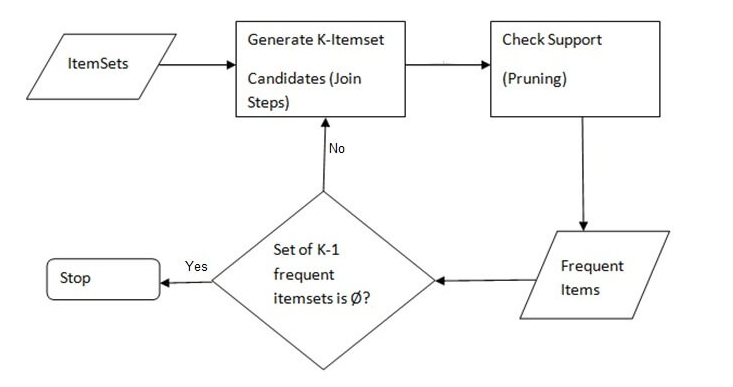
Step 2 Rule generation : Create
rules from each frequent itemset using the binary partition of frequent itemsets and look for the ones with high confidence. These rules are called candidate rules
Example :
Step 1
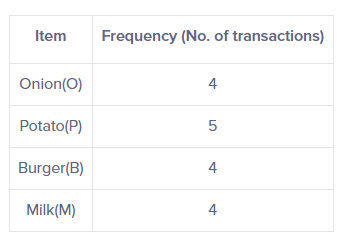
Let's take back our database from our prior example and set the support threshold to 50%.
First we have to create a frequency table of all the items that occur in all the transactions :

From there knowing that our support threshold is equal to 50%, we only retain the items for which the threshold value is equal or greater than 50% :
Once it's done, the next step is to make all the possible pairs of the significant items keeping in mind that the order doesn't matter, i.e AB is same as BA. To do this, we take the first item
and pair it with all the others such as OP, OB, OM. SImilarly, consider the second item and pair it with preceding items, i.e. PB, PM. WE are only considering the preceding items because PO (same
as OP) already exists.
=> So all the pairs in our example are OP, OB, OM, PB, PM, BM.
Now, once again, we count the occurences of each pair in all transactions and only keep those that are significant respectively to our threshold.
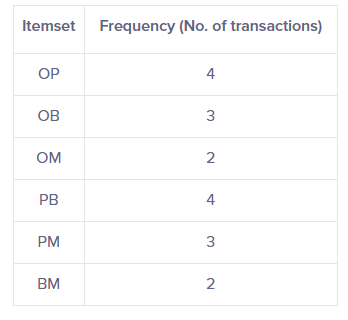
=> Significant pairs : OP, OB, PB and PM.
At this point, if we want to create a set of 3 items another rule called self-join is required. Accordingly to this rule, from the item pairs OP, OB, PB and PM we
look for two pairs with the identical first letter and so we get :
OP and OB , that gives OPB
PB and PM that gives PBM
Next, as previously we search for the frequency of our itemsets and can conclude from it that OPB is the only significant itemset.
Step 2
Now that we have looked at the Apriori algorithm with respect to frequent itemset generation, let's see how we can find association rules efficiently.
in this case it is pretty straightforward as taking back our previous result, where we found that OPB was the frequent itemset, we can easily spot that all the
possible rules using OPB are :
OP -> B
OB -> P
PB -> O
B -> OP
P -> OB
O -> PB
Alright so now that we have made a simple example of association rule mining with the Apriori algorithm by hand, let's move forward and implement it in a real case
with python.
Application
In this application, we will use the Apriori algorithm to find the association rules between different products on a basis of 7500 transactions registered over the course of a week at a French
retail store.
=> Click here for the database link
So first download the database on your desktop or on your google drive, and import the following libraries :
Once it's down we import our dataset and reformat it in order to take into account the specificity of the csv standard in our dataset :

From there we preprocess our data in order to transform our whole dataset in a big list where each of our transactions is going to be an inner list in the big
dataset outer list.
n.b. I agree that this processing of our data can be a bit troubling but it is nonetheless necessary as The Apriori Library that we are going to use in the
following require our dataset to be in the form of a list of lists.

Now let's build our Apriori model. Here we will search for product purchased at least 20 times per day so 140 times per week wich gives us support equals to 140/7500 = 0.18. Moreover, we will fix our minimum confidence at 35%, our lift value at 4 and our mini_length at 2 since we want at least 2 products in our rule.

(n.b: Those number are totally arbitrary so don't hesitate to choose your own specs)
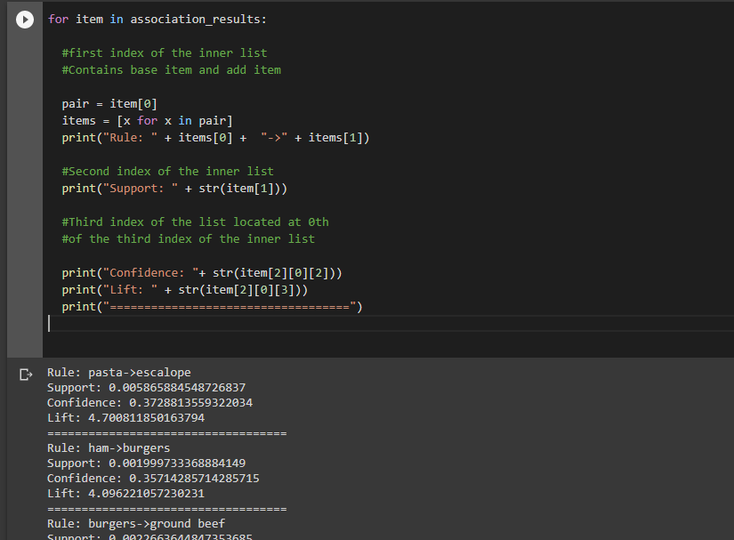
Observation :
From the first result we can see that pasta and escalope are commonly bought together. Also if we look at the different indicators, it appears that :
- 0.05% of all the transactions are containing the item pasta
- out of all the transaction containing pasta 37% also contains escalope
- it appears that escalope is 4.7 times more likely to be bought by someone buying pasta compared to the default likelihood of the sale of escalope
And that's it for tyhe Apriori algorithm ! ^^ So don't hesitate to play around with this algorithm on different datsets, and with your own parameters in order to
get a deeper understanding of it.
As always full code for this tutorial can be found here
I see you on the next one, in the meantime take care ✌️

All information/documents contained in this website rely solely on my personal beliefs, and do not constitute professional investment advice.
Be careful in your investment and do not invest more than you can afford to loose.
Contact :
e-mail: christophe.richon.pro@gmail.com